Autopilot: Testable Automated Behaviors for ArchiveWeb.page and Browsertrix
Web archiving can be complex and often tedious work, especially when trying to archive dynamic, infinitely complex content such as social media. A key goal of Webrecorder tools is to make web archiving simpler, and we've taken an important step with latest update to our tools. Over the last week, the Webrecorder team has been quietly testing our new automated, in-page behavior system, sometimes also known as Autopilot!
Autopilot in ArchiveWeb.page
Web archiving can be complex and often tedious work, especially when trying to archive dynamic, infinitely complex content such as social media. A key goal of Webrecorder tools is to make web archiving simpler, and we’ve taken an important step with latest update to our tools. Over the last week, the Webrecorder team has been quietly testing our new automated, in-page behavior system, sometimes also known as Autopilot!
The system is available in the latest release of ArchiveWeb.page extension and desktop app.
The ArchiveWeb.page Guide has been updated with a new page on how to use Autopilot.
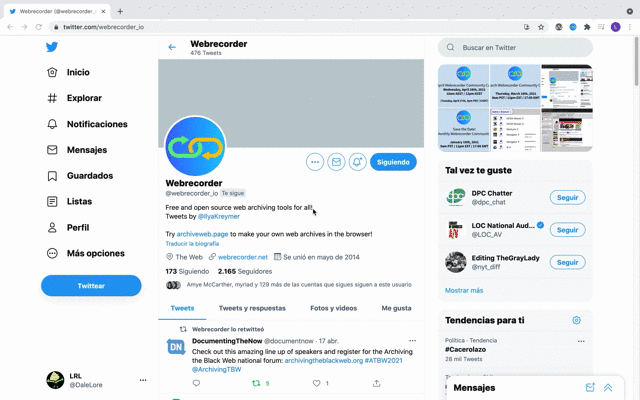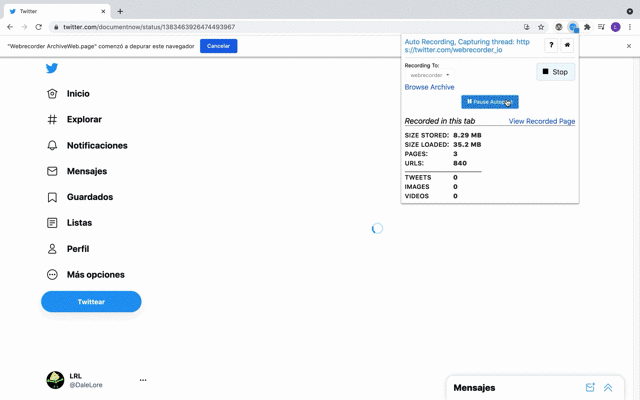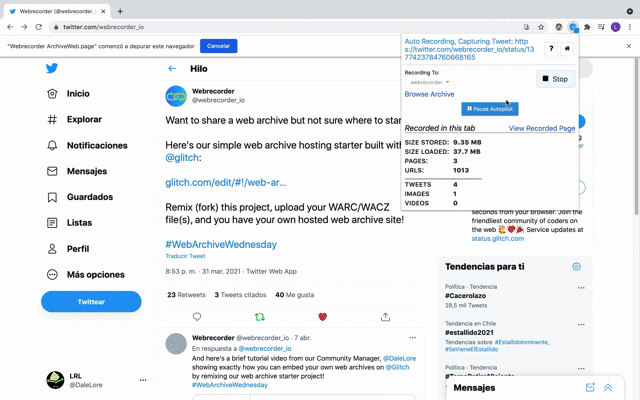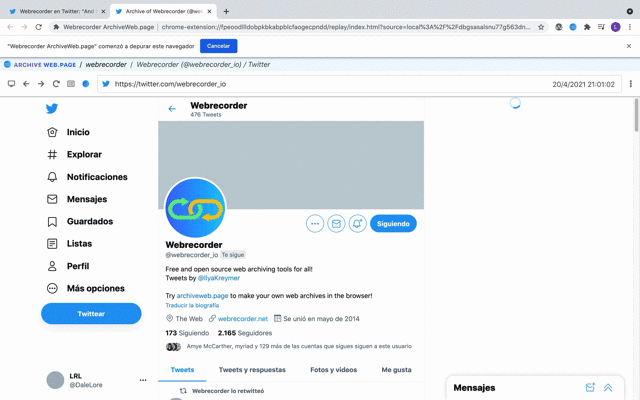
The automated behavior system allows the browser to be automated to perform custom interactions with a page to automate repetitive tasks, such as clicking and scrolling. The default, Autoscroll behavior, is designed to support any site with infinite scroll. (It works well on Yahoo Answers, helping archive those pages before they disappear!)
The system includes site-specific behaviors for the most commonly requested sites: Twitter, Instagram, and even Facebook!
The behavior for Facebook pages is the newest and most experimental, but we hope will it will make the job of those trying to archive social media slightly easier.
These behaviors perform complex interactions designed to capture the highly interactive elements of these sites, including infinite feeds, videos, photos and comments. The guide also includes a detailed overview of each behaviors functionality and limitations.
Autopilot in Browsertrix Crawler
The behavior system that forms the basis for Autopilot is actually part of the Browsertrix suite of tools, and is known as Browsertrix Behaviors.
The behaviors are also enabled by default when using Browsertrix Crawler, and can be further customized with command-line options for Browsertrix Crawler.
Browsertrix Crawler provides additional options for choosing which behaviors are enabled and provides options to view the behavior status log as the behavior is running.
The Hard Part — Automated Automated Testing
The first iteration of Autopilot was initially launched for Webrecorder hosted service (now Conifer), and Webrecorder Desktop App.
Over time, we’ve learned that as hard as it is to make the automated behaviors, maintaining them is even harder! Social media sites are not only complex, but also change frequently, and the web archiving community must inevitably play catch-up.
There is no doubt that the site-specific behaviors will break and need to be maintained, and require consistent upkeep.
To make this a bit easier, all Autopilot/Browsertrix Behaviors are automatically tested daily, using GitHub actions.
The tests run a small crawl using Browsertrix Crawler on a fixed social media account, created specifically for testing, to ensure the basic functionality of a behavior (clicking on photos, playing videos, going through feed, etc…) remains unchanged. Each branch or pull request for the behavior system is also tested with a basic crawl. Of course, these tests are a bare minimum to the potentially infinite complexity of archiving dynamic social media sites, but we hope this is a start to making behaviors more maintainable.
We’ve also learned that it is important to help uses manage expectations. With these tests, we can quickly find out when particular behaviors break, and users of Webrecorder tools can also see which behaviors are currently working and which ones from the behaviors overview page or from GitHub.
With this testing in place, we hope to be able to address broken behaviors more quickly, and let users know when they are broken.
Browsertrix Behaviors — Just add Browser
The behavior system is intentionally designed to run entirely in the browser and can work on any modern browser. While we test it with Browsertrix Crawler, the behaviors can be injected directly into a browser in any way (including just copy and paste! and is not tied to a particular crawler.
The goal was to make the behavior system usable in any kind of browser-based crawler, and encourage community contributions of new behaviors!
Are there certain site-specific behaviors you’d like to see, and can you help create? If so, feel free to open an issue on GitHub, or discuss on the forum.
We hope to create more guidelines and documentation on how to contribute behaviors in the future. Stay tuned!