An update on the WACZ format
It has been over two years since we've first introduced the WACZ format and I wanted to give a brief update on exciting new tools and integrations of WACZ, and also provide a glimpse of what's next in the evolution of the format.
New WACZ Tools and Integrations
It has been over two years since we’ve first introduced the WACZ format and I wanted to provide a brief update on exciting new tools and integrations of WACZ, and also provide a glimpse of what’s next in the evolution of the format.
WACZ support in Perma Tools

We are thrilled to share that our colleagues at Harvard LIL, who run the perma.cc have released several new tools that leverage the WACZ format, including:
-
js-wacz — Javascript library for WACZ, designed to be compatible with our original Python py-wacz
-
Scoop — a standalone archiving tool for generating signed WACZ files for single pages. The tool adheres to the WACZ Signing spec and also uses our Browsertrix Behaviors for improved high-fidelity capture.
-
wacz-exhibitor — a tool for bootstrapping ReplayWeb.page viewer embed system embed with a bundle Nginx servicer, custom cache layer and additional wrapping via an iframe.
You can read more about Scoop on this blog post from Matteo Cargnelutti, the lead developer of the tooland the rest of the Perma Tools suite at https://tools.perma.cc/.
It is exciting to see a growing open source ecosystem around the format and high-fidelity archiving!
Save WACZ Now!
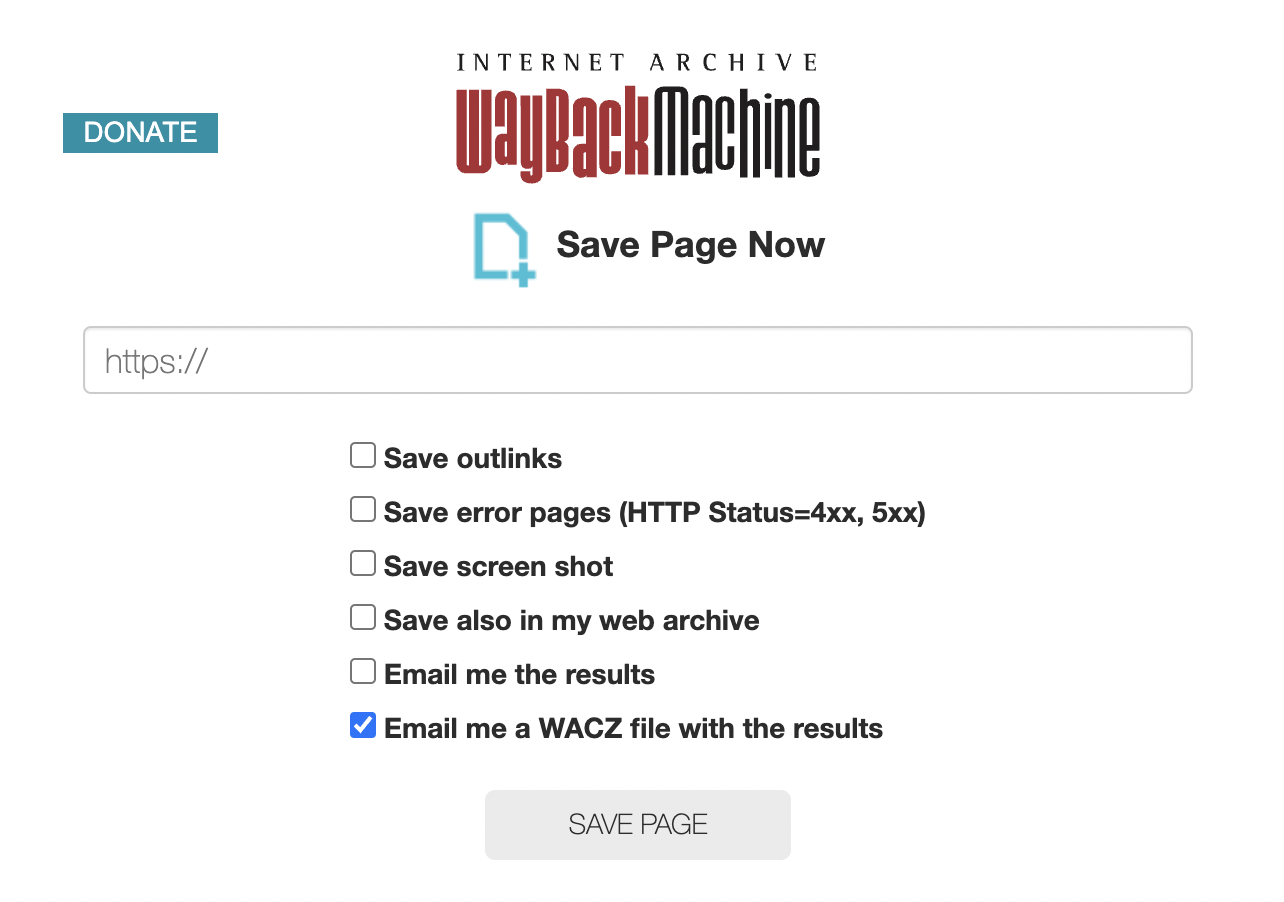
We are also excited to share that Internet Archive’s Save Page Now system now provides support for emailing users a copy a WACZ files created from an on-demand capture using this service.
Our colleague ed-summers describes testing out this feature in a recent blog post
We appreciate IA’s support in helping make web archives more portable via the WACZ format!
WACZ in AP News
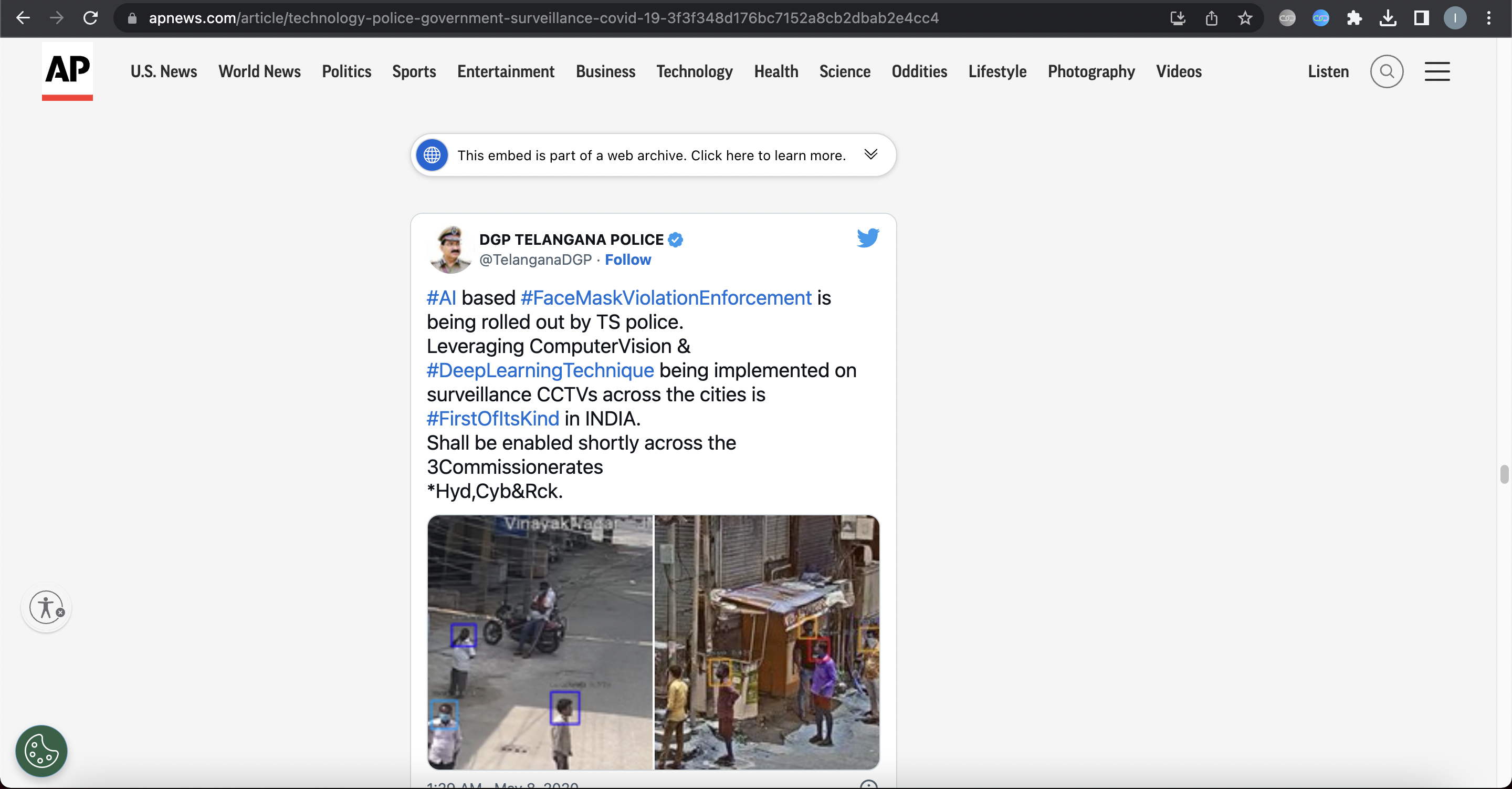
Our collaboration with Starling Lab has led to an experimental use of a signed WACZ for an embedded Tweet in an AP News article, which you can read here.
The tweet uses our archival ‘receipts’ provenance view to indicate that this archived tweet was created on the specified date and time, by Starling Lab server! Even if the original tweet is removed or edited, we can digital proof that this web archive was created by Starling Lab (signed by certificate issued to authsign.starlinglab.org) This is all possible by using a WACZ signed according to the WACZ Signing and Verification Specs created using an instance of Browsertrix operated by Starling.
What’s next For WACZ Spec
These are just some of the examples of the growing adoption for the WACZ format. (If you have more examples, please share with us).
We also wanted to provide an update on new specification work happening around the WACZ format.
WACZ on IPFS Custom Storage Spec

One of the new things we are working on is how to put WACZ files on IPFS, in a way to maximize deduplication by splitting the files in a certain way along file and WARC record, and WARC payload boundaries.
The spec covers how to put general ZIP files, how to put WARC files (compressed or uncompressed) onto IPFS and the various trade-offs involved.
By following the spec, it will be possible to leverage IPFS’s content addressing to automatically deduplicate the same archived content, even if stored in different WARC files inside different WACZ files!
You can read the current draft of the spec here
The ArchiveWeb.page extension and our Save Tweet to IPFS tool are already using this spec.
For example, if two different users save the save tweet, the actual content will be automatically deduplicated, while the WARC headers will be new, resulting in storage savings overall.
Look forward additional blog posts describing this spec in more detail!
Multi-WACZ or WACZ Collections Spec
We are also working on a spec for how to combine multiple WACZ files to create collections. A single WACZ file can only be so big (though we’re exceeded 1TB with the format last year), and we need a way to group WACZ files, either from the same crawl, or multiple crawls, into a user-defined collection.
The ‘Multi WACZ’ spec will be all about creating collections of persistent web archives, and will be a Frictionless Data package that specifies URLs to WACZs files logically grouped together.
If you are interested in this spec, please see the pull request and GitHub Issue and feel free to provide feedback!
We will provide additional information as this spec develops!
Improvements and Suggestions Wanted!
We are always looking for further improve the spec as web archiving continues to evolve. Are there other data you’d like to see in the WACZ format, or other feedback in general? If so, feel free to leave an issue directly on our specs repo!
EDIT 2024-05-22: “Browsertrix” was previously referred to here as “Browsertrix Cloud”. This post has been updated to reflect the new name.