Browsertrix 1.9
Browsertrix has had some big improvements since our last blog post, lets take a look at some of the more recent ones!
A Quick Look Back at 2023
It has been almost two years since we initially announced Browsertrix! Since then, we’ve been pretty much solely focused on developing our next generation cloud-based archiving platform. One of the downsides of this sole focus is that sometimes you forget to update the company blog and actually tell people about what you made! I’m not going to go back and write update posts for every major release we’ve done (there have been eight!), but here are some of the more recent highlights if you missed them:
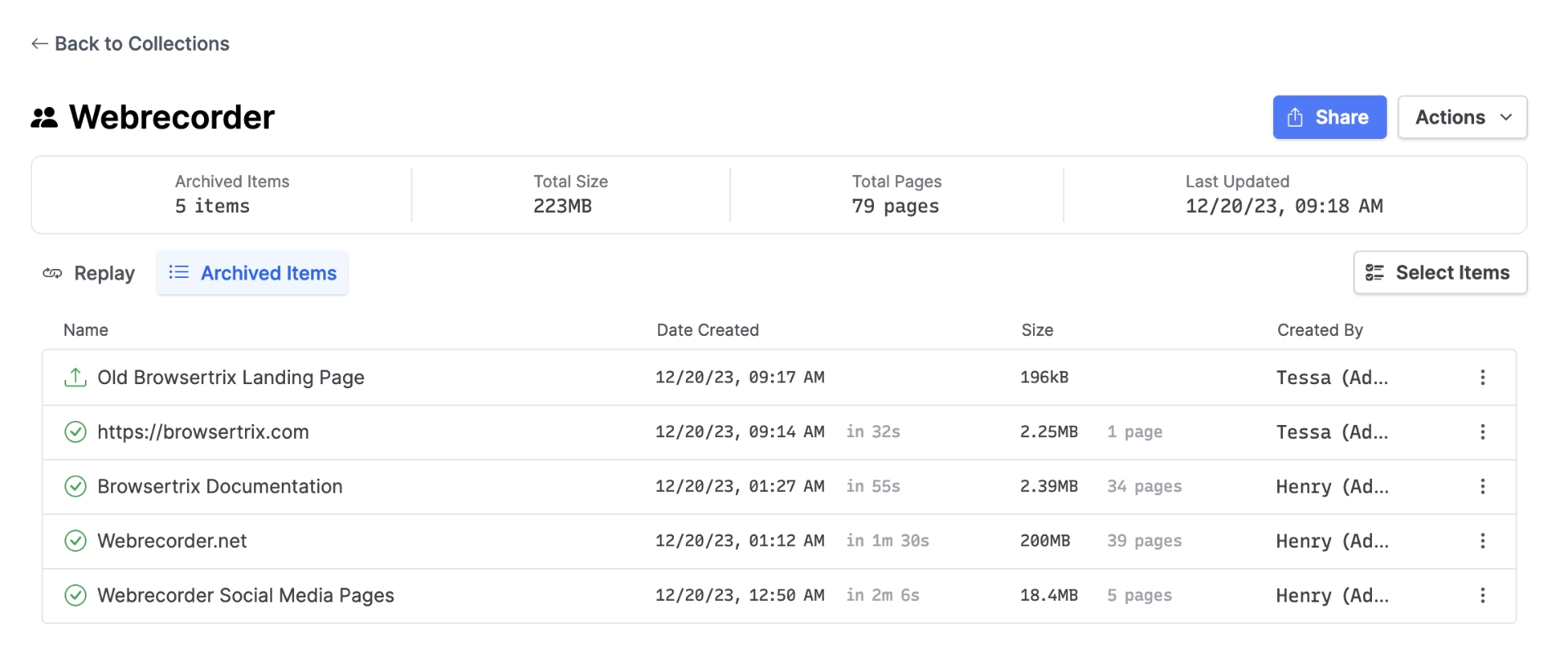
Collections
In 1.6 we added collections, the ability to add archived items to multiple different groups for sharing and export! Collections serve as the base for future curation features, but right now they allow for both crawls and uploads to be replayed, downloaded, or shared together as one package.
Because both uploads and crawls share their data within a collection, they also allow you to manually patch automated crawls created through our ArchiveWeb.page browser extension. If elements on a site you’ve tried to capture in Browsertrix aren’t available when replaying the crawl but are available when you capture the page with ArchiveWeb.page, try uploading a WACZ from ArchiveWeb.page and adding both to a collection!
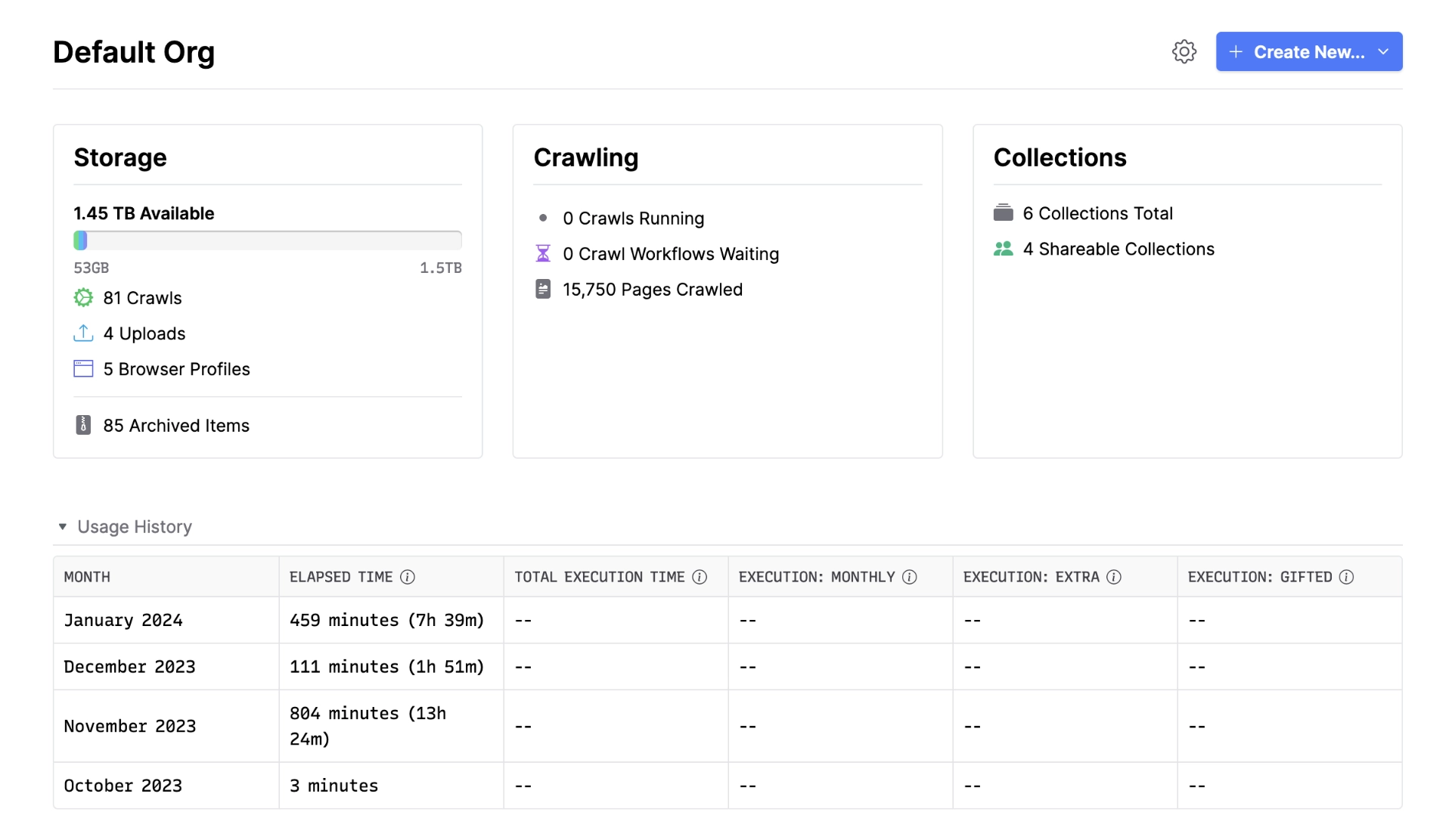
Dashboard & Execution Time
In 1.7 we added the Overview page which displays key org metrics for storage and crawling. In 1.9 we’ve updated the usage history table to give you more granular stats on your execution time, separately listing the execution minutes used per-month based on how you’re charged for them.
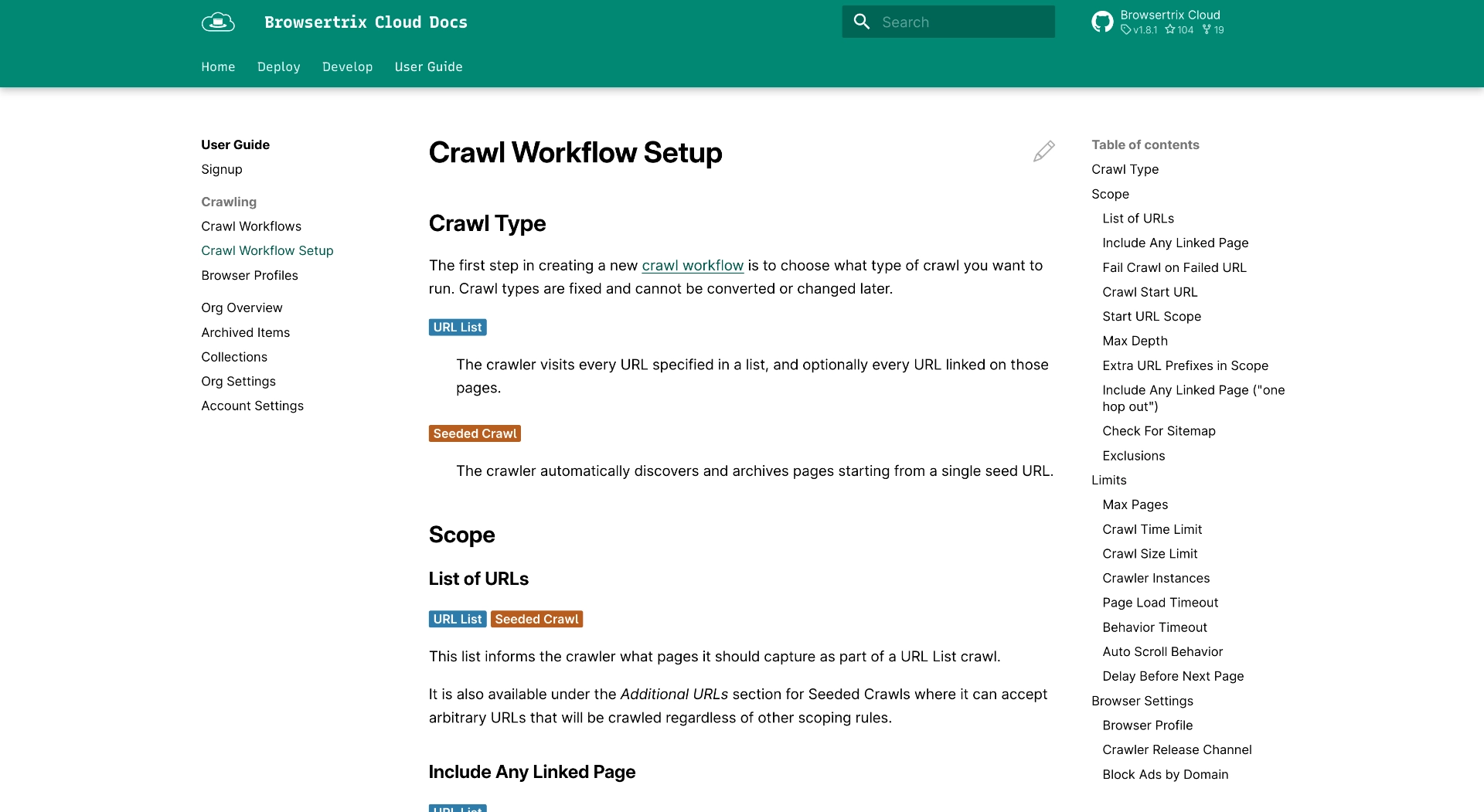
Documentation
We may not have updated the blog much, but we definitely upgraded our docs! Browsertrix now has a full user guide using the excellent Material for MKDocs theme. One page I’m personally proud of is our extensive list of every crawl workflow setting, a handy reference if the in-app help text isn’t quite enough.
1.9 Release!
Crawler Version Selection
We frequently release beta versions of Browsertrix Crawler, the core component of our software actually responsible for capturing websites. Up until now, the version the app uses has been set by us, soon we’ll be providing you with some options! Release channels can now be set on a per-crawl basis so if we’ve implemented a fix in the latest beta for a site you’re trying to crawl, you can use it — while keeping in mind that there may be other unresolved issues that aren’t quite ready for prime time yet and that’s why it’s a beta version. But you knew that already, right?
More information can be found in the Crawler Release Channel section of the workflow setup page.
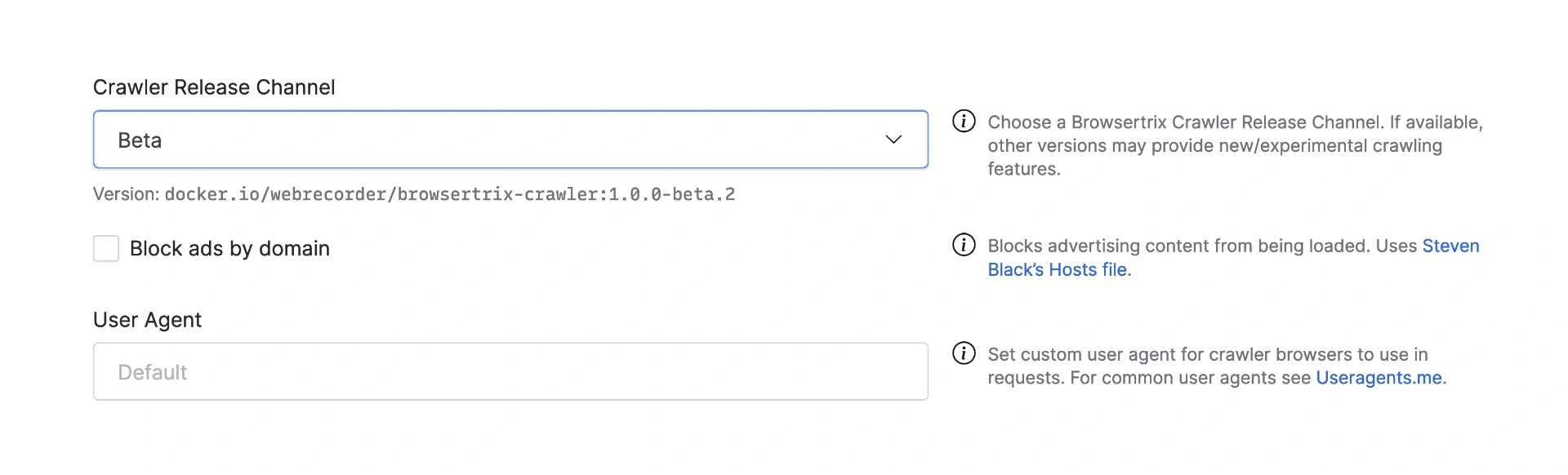
Custom User Agents
Release channels aren’t the only new crawling feature though, we’ve also added the ability to set a custom user agent that the crawler will use to identify itself to websites. In addition to bypassing sites that try to restrict which browsers can access them — something they generally shouldn’t be doing anyway — this feature is also useful for some of our larger clients for coordinating with publications to ensure their crawls don’t get blocked.
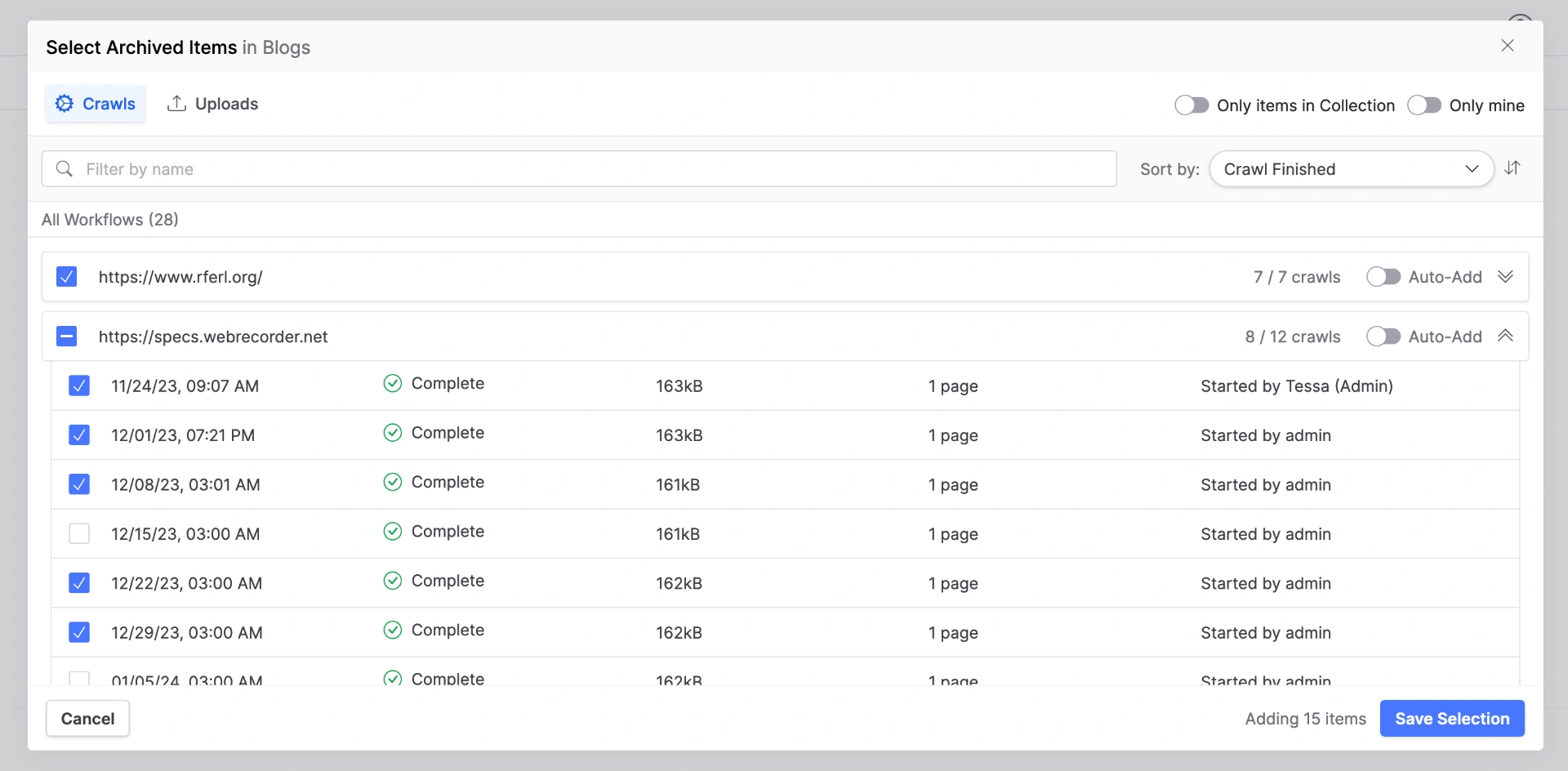
Updated Collection Selection UI
While we updated some of this to remove the clunky multi-stage setup and editing process for collections in 1.8 (if you know, you know), the release of 1.9 completes our overhaul to the collection content editing process. “Auto add” can be toggled for workflows right in the collections editor, and archived items in and out of the collection are now displayed in the same window giving us more room to display information about each item.
Fixes & Small Things
As always, a full list of fixes (and additions) can be found on our GitHub releases page, but here’s some of the big small stuff:
- The “workflow settings” tab that displays the current workflow settings and crawl settings tab that displays the workflow settings used for that crawl now display the same data without any discrepancies. #1473
- Useful for nailing down what might have changed when crawling the same site multiple times with different settings!
- We’ve increased the max width of the app. More data on the screen at once! #1484
- Fixed a memory leak, now the server doesn’t have to restart every day! #1468
- Run on Save is now only toggled on by default when creating a new workflow. #1458
- No more workflows running by accident!
What’s next?
We’re busy developing the initial version of our assistive quality assurance tools, currently focused on screenshot analysis of captured content. While there’s still a little ways to go before it’s ready for testing, everyone is pretty excited to get that into your hands. Look for it in the next major release! 🙂
If you’re interested in signing up to crawl with Browsertrix for your institution, check out the details at Browsertrix.com.
Comments
Reply on Bluesky to join the conversation.

Webrecorder @webrecorder.net · 2 years ago
Crawler Version Selection: We frequently release beta versions of Browsertrix Crawler, the core software actually responsible for capturing websites. On our instance you'll now have some options for which version you want to use!
1
0
0
Webrecorder @webrecorder.net · 2 years ago
Also in the above image... Custom User Agents! Identify yourself to websites, or get around content that is restricted to a certain browser (bad!)
1
0
0
Webrecorder @webrecorder.net · 2 years ago
Updated Collection Selection UI: No more double panel UI! Also "auto add" can be toggled for workflows in the collection editor.
1
0
0
Webrecorder @webrecorder.net · 2 years ago
Next major release: Assistive QA tools! We're already in the middle of developing these, but you can expect comparisons of archived content as it was captured at crawl time VS as archived. Look for it in 1.10! :)
0
0
0