Browsertrix 1.12: Proxies, Crawling Defaults, and Simplified Workflow Creation
Proxies, crawling defaults, and simplified workflow creation!
Emma Segal-Grossman/ Senior Software Developer
Proxies
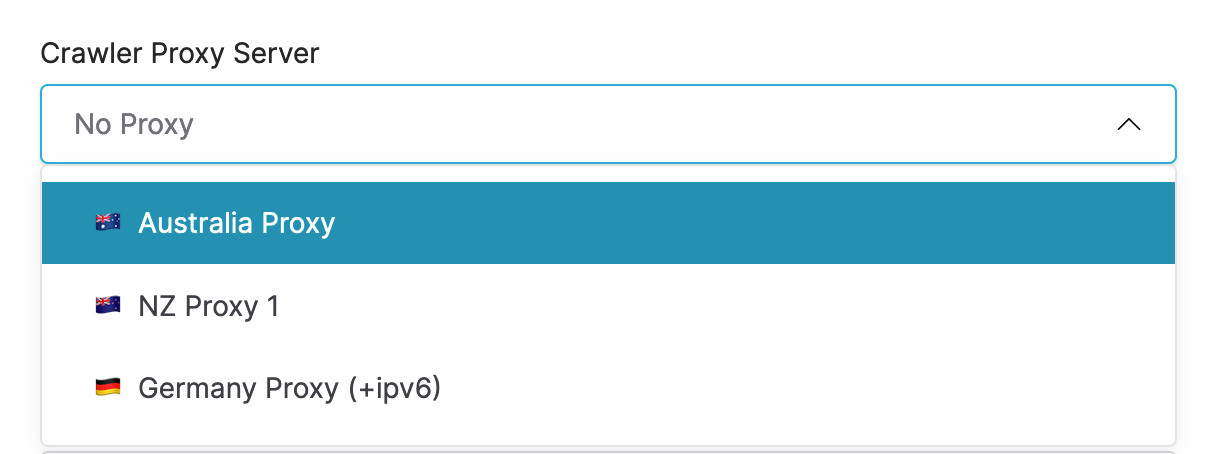
We are very excited to announce the release of Browsertrix 1.12, including a long-anticipated new feature: crawling through dedicated proxies! Browsertrix can now be configured to direct crawling traffic through dedicated proxy servers, allowing websites to be crawled from a specific geographic location regardless of where Browsertrix itself is deployed. Want to crawl geographically-restricted content? Ensure your archived items reflect a local user experience? Crawl from a static local IP without the maintenance burden of self-hosting? All of this is now possible!
In our hosted Browsertrix service, proxies will be an optional paid feature available to users of Pro plans. We’ve started testing proxies with a few existing Pro users and will continue to refine our proxy offerings based on what we learn in practice.
If you are a current Browsertrix service customer, and want to try a local proxy in your region, let us know.
We’ve also added detailed documentation for folks who self-deploy Browsertrix on how to configure proxies to use with Browsertrix.
Once proxy servers are configured and made available to an organization, they can be selected per-crawl workflow or set as an organizational default so that all new workflows use a specific proxy by default (see more about crawling defaults below!).
Simplified Workflow Creation
We’ve simplified the process for creating a new crawl workflow. Previously, users had to select between URL List and Seeded Crawl workflow types before any other configuration. We heard loud and clear that this was confusing.
Now all crawl scopes types are available in the same interface without needing to go through a dialog, and we’ve quick-linked the different scope types from the New Workflow button in the Crawling tab. Your browser will even remember the last crawl scope type you used and set it again the next time you create a crawl workflow.
We’ve also added a Single Page scope type to make it as clear as possible what to do when you only need to archive a single page.
In Case You Missed It
We added a few features in 1.11 point releases since the last blog post, so here’s a few words on those!
Crawling Defaults
Browsertrix now includes new per-org crawling defaults! We heard from users that it would be helpful to be able to set certain crawling defaults for things like crawl limits, browser profiles, user agents, and the browser’s language setting. You can now find these in the Crawling Defaults section of Org Settings. Set it once and forget it, with the confidence that your default settings will be used in every new crawl workflow unless you manually override them.
Breadcrumb Navigation
We’ve added breadcrumb navigation to many pages in the app to help you navigate and situate yourself. When you’re viewing crawl workflows, archived items, collections, and browser profiles, take a look up towards the top of the page for the new breadcrumbs.
New Documentation Sidebar
Last but certainly not least, we’ve integrated documentation right into Browsertrix in specific places where referencing the docs might help you most! Specifically, check out the “Setup Guide” button in the upper-right corner of the workflow editor. Getting help with understanding the purpose of workflow options has never been easier.
What’s next?
We’re already hard at work on features that will go into Browsertrix 1.13, including custom org storage. Soon you’ll be able to bring your own S3 bucket to use for crawling outputs, browser profiles, and other data generated by Browsertrix, giving you more flexibility and control than ever.
Sign up and start crawling with Browsertrix!
Comments
Reply on Bluesky to join the conversation.

Webrecorder @webrecorder.net · 2 years ago
A lot is happening right now, especially on the web. Know that the Webrecorder team is here to support you. We offer dedicated tools to assist with your web archiving needs. We are happy to offer a free trial,reach out to sales@webrecorder.net to try Browsertrix today!
1
4
6
