
Reduce Storage with Crawl Deduplication
A new feature to save you storage space.
Tessa Walsh/ Senior Applications & Tools Engineer
Data storage has gotten expensive. It’s an unfortunate trend that seems unlikely to reverse. With deduplication in Browsertrix, we’re making it a little easier to use less storage.
Deduplication (“dedupe”) shows up in your day-to-day life in a few ways that usually go unnoticed: most commonly, in filesystems (via techniques like copy-on-write and hard linking), backups, and large data storage systems. Fundamentally, the idea is that any time you have a piece of data that’s the same as another piece of data, you only really need to store one copy of it. In the web archiving world, this has been possible for a while in the form of “revisit” records in the WARC specification.
Browsertrix now supports crawling with a deduplication index, which lets our crawler reference existing data as it runs – I’ll explain how it works in more detail later. We’ve been working on it for a while, and we’re excited to get it out into the world. First, here’s Tessa to walk you through how to use it:
Our Approach to Dedupe
We’ve built deduplication on top of Collections, our curation tool. You may already be using collections to organize and curate crawls; deduplication for a collection can be enabled in just a couple minutes. As mentioned above, our crawler is now able to use an entire collection as a basis for deduplication, writing revisit records to reference data that already exists in the collection. This means you get predictable control over what is and isn’t deduplicated, giving you the flexibility to accommodate a variety of different archiving workflows.
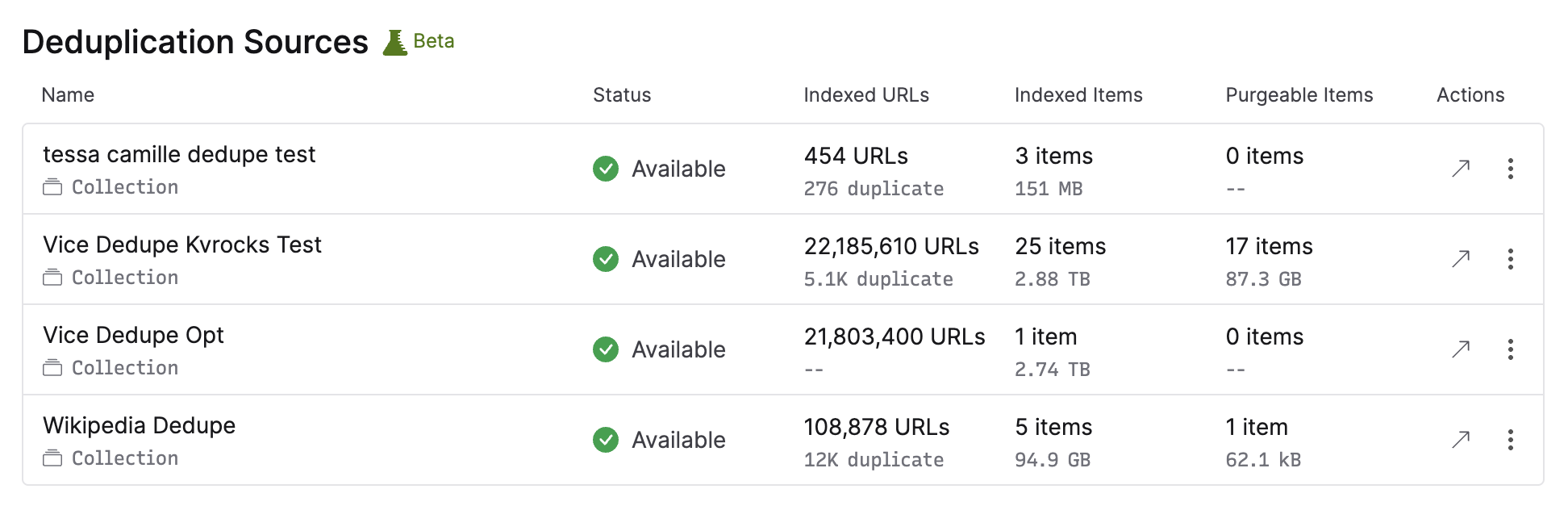
To make this work, we use a deduplication index. This keeps track of all the different resources present in a collection, allowing the crawler to efficiently match incoming crawled data to existing records. Critically for some advanced use cases, this index is preserved when removing content from Browsertrix, which means that you can continue to crawl with deduplication even if you regularly export data out into your own archival and replay systems. Only want to deduplicate against items currently in the collection? No problem, organization admins have the ability to “purge” the index and rebuild it from the collection’s current items at any time.
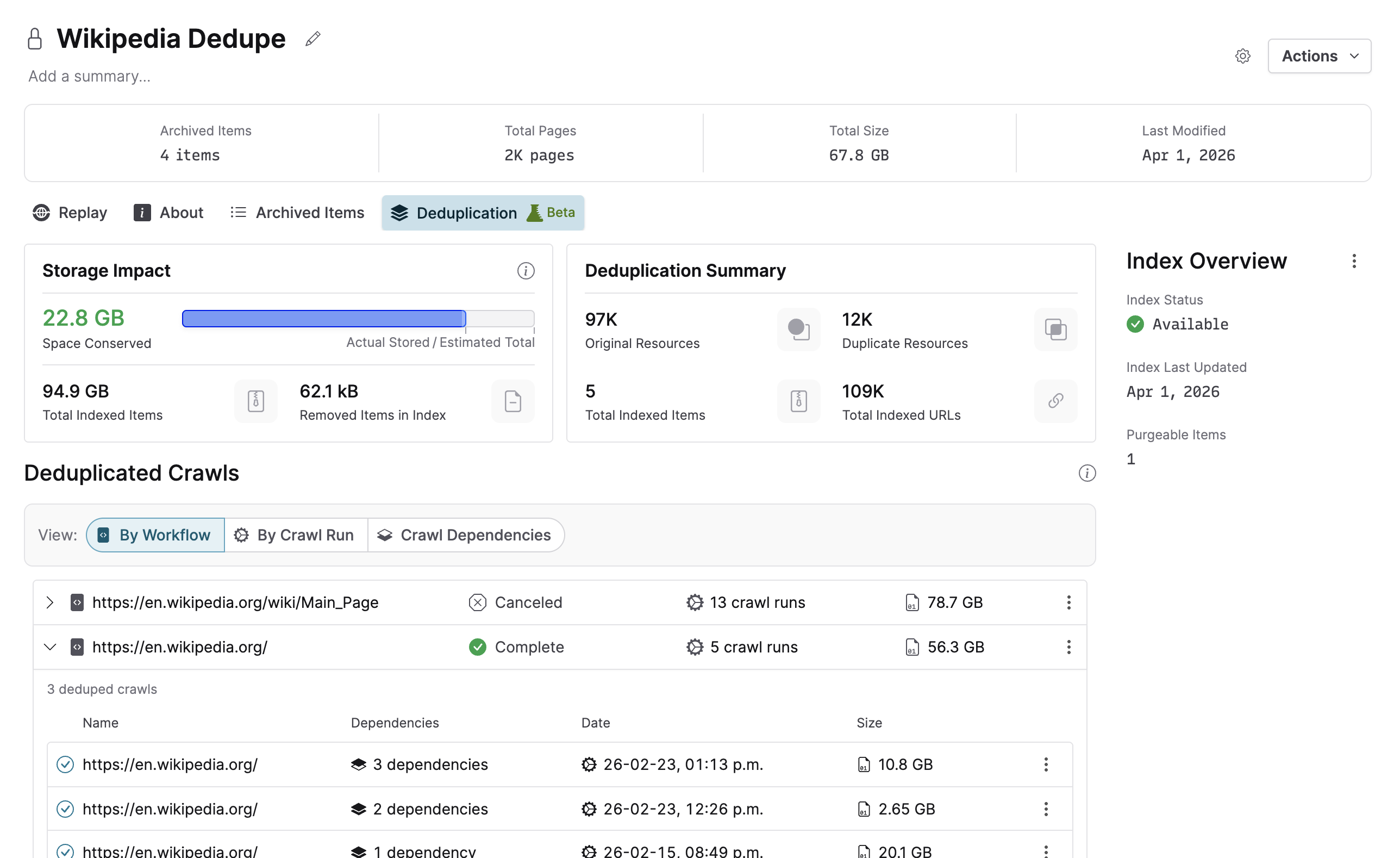
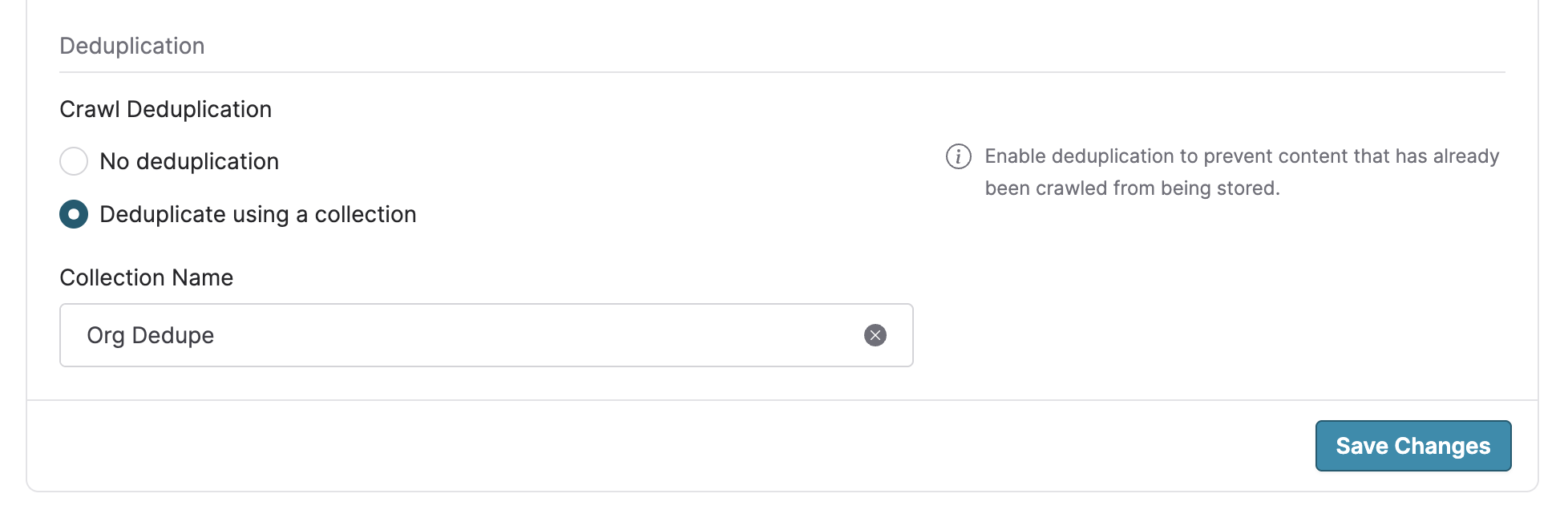
For org admins, you can see an overview of all deduplication activity in your org settings, and you can also set a default deduplication source for all new crawl workflows so that you can deduplicate everything across your entire org.
So Should I Turn It On?
Deduplication introduces something new into Browsertrix: dependencies between archived items. Because revisit records written during crawling point to other archived items (previous crawls, or uploaded WACZ files), full replay of deduplicated crawls relies on those items being available.
Inside Browsertrix, resolving these dependencies is handled for you automatically so your crawls and collections replay exactly as expected. We’ve added indicators throughout the application to make it clear when a crawl is dependent on other items, and to easily see those dependencies. Deduplication lets you make the most of your Browsertrix subscription by letting you do more with the same storage limits.
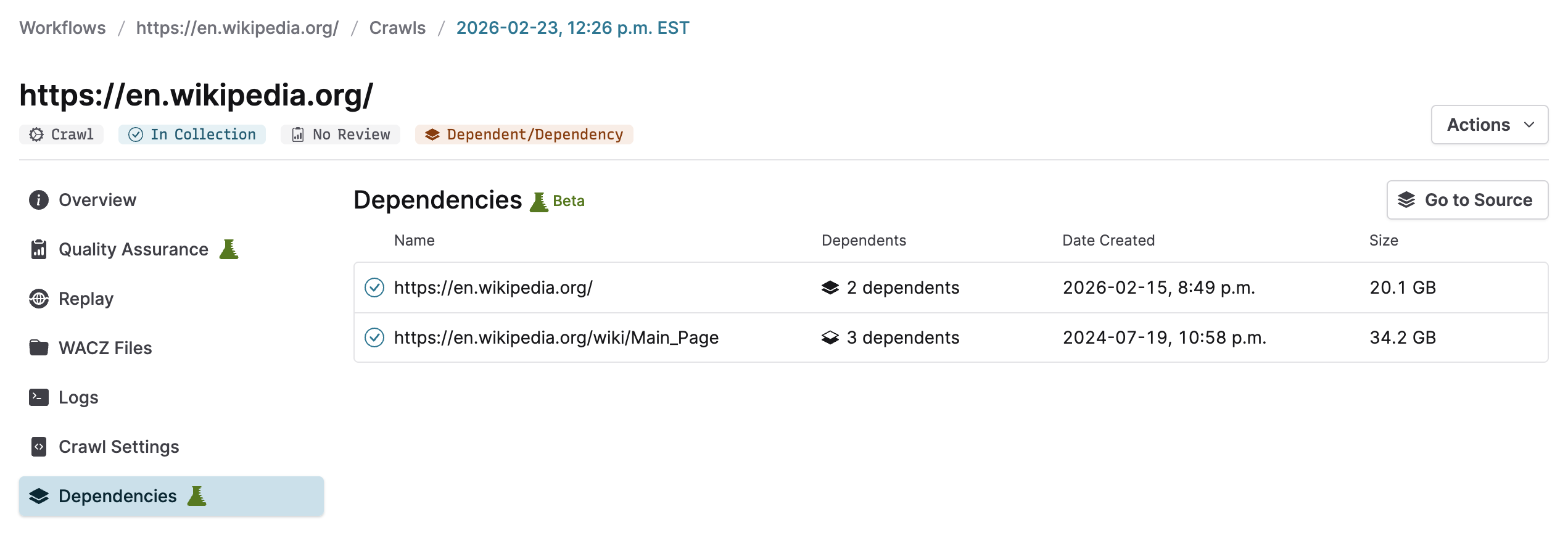
If you are a user who regularly exports your WACZ files out of Browsertrix to store and replay in other systems, then you may want to consider the other tools in your toolchain to see if deduplication is the right fit. If you export all of your WACZ files routinely and put their contents into a wayback machine-style replay system like pywb, the revisit records written during deduplication will resolve automatically.
If you need each downloaded WACZ file to be fully self-contained for replay, we’ve added an option to download any deduplicated crawl with all of its dependencies as a single larger WACZ file. This option ensures that you always have the ability to download a crawl along with everything it needs to replay perfectly. If you are doing this for all of your WACZ files, however, the extra disk space used by bundling each crawl’s dependencies into every download may negate the storage savings otherwise gained from deduplication.
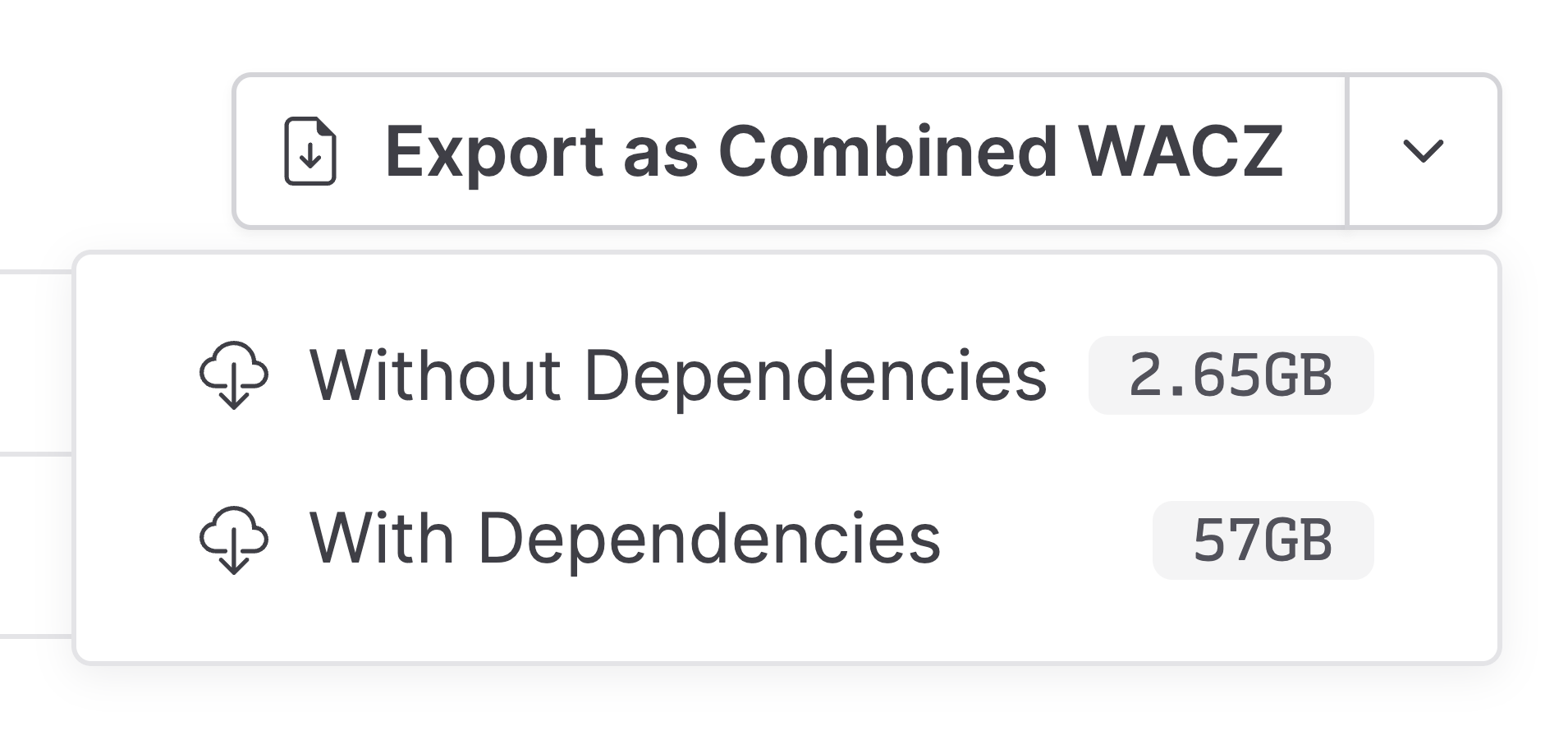
Deduplication is already available to select orgs on our hosted service. If you’re interested in trying it out before we make it available to everyone, let us know – we’d love to get your feedback! If you’re self-hosting Browsertrix it’ll be available by default as of v1.22.
Check out the Deduplication page in the user guide for a more detailed walkthrough and explanation.
Incremental Crawling, and More
We’re already working on expanding dedupe, including features that’ll allow you to skip crawling pages you’ve already crawled entirely in order to save both space and crawling time. We’re also building a system to more dynamically handle rate-limiting during crawling, which will help you more effectively crawl flaky or unstable sites. Stay tuned!
Comments
Reply on Bluesky to join the conversation.

Reality Ausetkmt @ausetkmt.bsky.social · 3 months ago
Oh my goodness my goodness my goodness can I possibly get in on this? Yes I am crawling these AI streets every night and this may very well make my trips shorter and more prolific. Looking forward to hearing from you soon with good news of inclusion
0
0
0
